A Kanban Board for Human and AI Coding Agents: Plan, Build, Review with Claude Code, Codex Agents Through Linear
Forking OpenAI's Symphony to create a Plan → Implement → Review pipeline that turns Linear tickets into collaboration board for faster merged code — with RepoPrompt for focused context, cmux for agent visibility, and a human in the loop
Have you ever wondered: what does it actually look like when collaborating with AI agents to manage your dev workflow through a Kanban board?
Not the demo version. Not the “watch an agent write a todo app” version. The version where I wake up, check my Linear board add whatever tickets i will be doing today, check three agents have been working on three different issues overnight — each following a plan I approved before going to bed, comment on their questions or approve moving ticket to next step.
Here’s how it works.
Why I Forked Symphony
OpenAI released Symphony — an Elixir-based orchestrator that polls Linear, spins up workspaces, and dispatches agents to work on issues. It’s genuinely elegant. The OTP supervision tree, the workspace isolation, the polling loop — it’s solid infrastructure.
But using it on real projects hits walls fast.
Symphony has one mode: throw an agent at a ticket. There’s no separation between understanding a problem and solving it. No human checkpoint before implementation starts. No way to watch what the agent is doing. And critically — no way to use Claude Code. It’s Codex-only.
The goal was something that matches how development actually works: understand first, plan, get approval, then build.
The Three-Phase Pipeline
Instead of “agent goes brrr on a ticket,” every issue now flows through three distinct phases mapped to Linear board states:
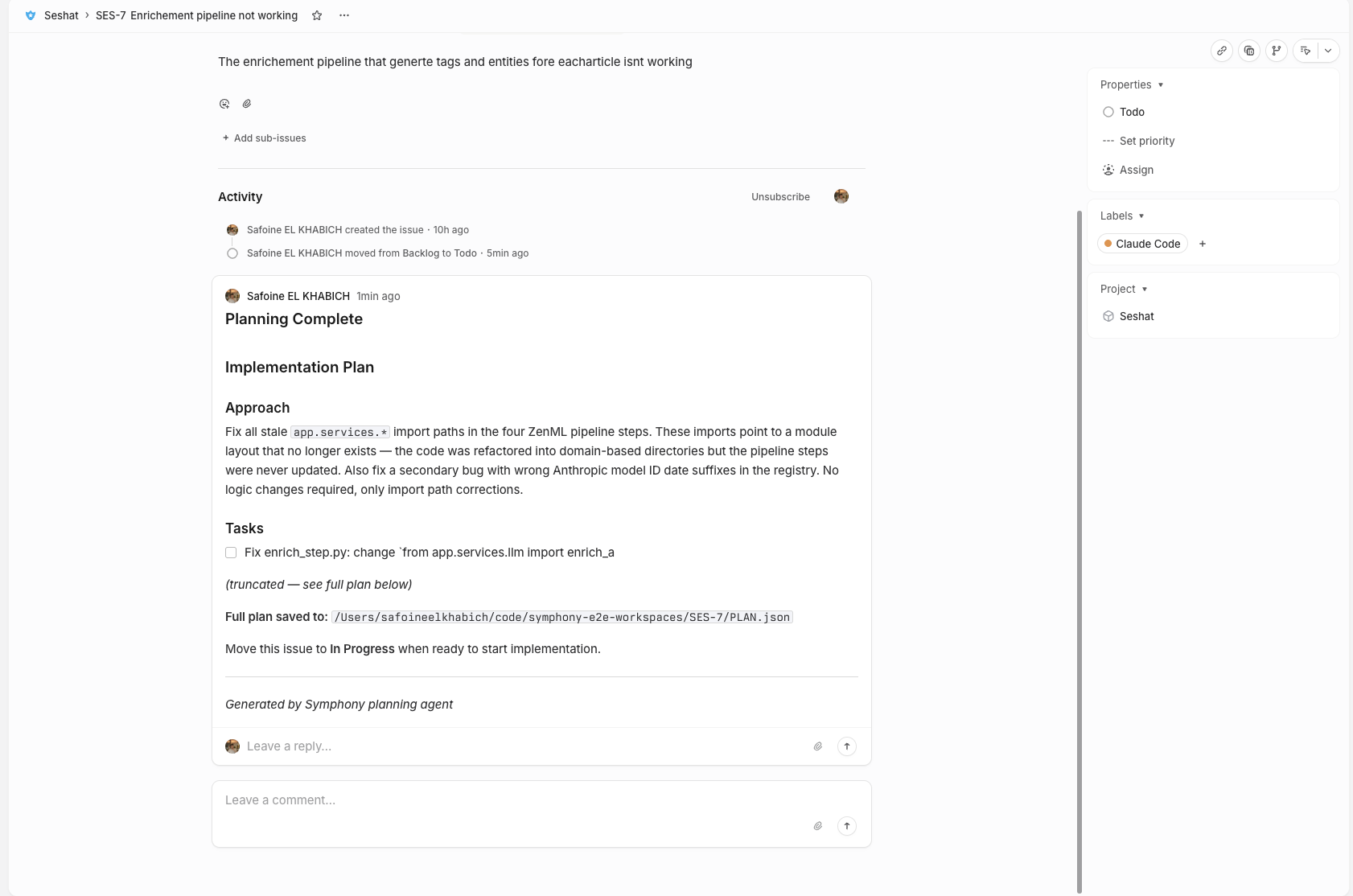
Todo → Plan. A planning agent investigates the repo, gathers context, and produces a structured PLAN.md. It posts a summary to the Linear ticket. Then it stops. The ticket stays in Todo. I review the plan when I’m ready.
In Progress → Implement. I read the plan in Linear, maybe ask a follow-up question (the agent detects my reply and re-plans with that context), and move the ticket to In Progress when I’m satisfied. The implementation agent picks up PLAN.md and follows it.
In Review → Review. When implementation completes, a review agent examines the diff. APPROVED moves to Done, CHANGES_REQUESTED sends feedback back.
The key insight came from reading OpenAI’s Harness Engineering article: plans should be first-class artifacts, not ephemeral reasoning. My PLAN.md persists in the workspace. If an agent fails on turn 5, the plan survives. The next attempt picks up where it left off.
The Human Gate
This is the piece that matters most in practice. When planning completes, nothing auto-transitions. I review the plan — posted right in the Linear comment thread — and decide when to start, The agent itself adds either Waiting Humain Feedback or Waiting Humain Approval depending on wither it needs my choice/feedback or just done and waiting for task to be moved to the next kanban pipeline step.
It sounds small. It’s the difference between an agent that goes off the rails on misunderstood requirements and one that builds exactly what I asked for.
There’s also a question/answer loop. If the issue description is too vague, the planning agent saves QUESTIONS.md instead of a plan. Symphony detects when I reply on the Linear issue and re-dispatches planning with my answers as context. It’s asynchronous collaboration between me and the agent, mediated entirely through Linear comments.
Planning agent → Produces PLAN.md → Posts summary to Linear → Waits
↓
I read plan, move to "In Progress"
↓
Implementation agent reads PLAN.md → Builds
Adding Claude Code as a Backend
Symphony was built for Codex only. But nothing is stopping us from supporting both Claude Code and Codex, adding Claude Code as a backend was a natural next step.
The AgentBackend behaviour defines a clean interface — start_session, run_turn, stop_session — and both Codex and Claude Code implement it. The DispatchRouter picks the backend per state from config:
pipeline:
state_actions:
"todo":
action: plan
backend: claude_code
max_turns: 5
"in progress":
action: agent
backend: claude_code
max_turns: 20
"in review":
action: review
backend: claude_code
max_turns: 3You can even mix backends or give and change used coding agent from a step to another — Claude for planning (where its reasoning shines), Codex for implementation. Currently running Claude for everything, but having the option is nice.
Under the hood, the Claude Code backend spawns claude -p "<prompt>" --output-format stream-json, parses NDJSON events in real-time, and maintains session continuity via --resume <session_id>. The session ID persists to .symphony-session-id in the workspace, so if an agent fails on turn 5, turn 6 picks up the same conversation.
One gotcha: Claude Code requires a TTY to produce stream-json output. Without one, it produces nothing. In headless Port mode, wrapping it in script -q /dev/null allocates a pseudo-TTY and fixes this.
Making Agents Visible with cmux
The biggest frustration with agent orchestrators is that agents run as headless subprocesses. You’re staring at log lines, guessing what’s happening. Is it stuck? Is it exploring the wrong directory? Is it about to rm -rf something important?
The solution: run agents in visible cmux terminal tabs.
When cmux_visibility: true, each dispatched agent gets its own named tab — “SES-5 In Progress”, “SES-12 Todo” — and you can switch between them to watch any agent in real-time. The NDJSON events stream through a display filter that shows human-readable summaries: tool calls, reasoning steps, file edits.
┌─────────────────┬──────────────────┬──────────────────┐
│ SES-5 In Prog │ SES-12 Todo │ SES-18 Review │
│ │ │ │
│ ⚙ Edit: lib/... │ → context_builder│ ✓ APPROVED │
│ ⚙ Bash: mix t.. │ → get_file_tree │ │
│ ✓ Tests pass │ Producing plan.. │ Moving to Done │
└─────────────────┴──────────────────┴──────────────────┘
If cmux isn’t available, it falls back to headless Port mode. Zero config required.
RepoPrompt: Stop Burning Tokens on Blind Exploration
Before integrating RepoPrompt, Symphony agents were spending millions of tokens doing find . -name "*.ex" and reading files one by one. Expensive and slow.
Now, the planning agent’s first instruction is: use context_builder. This MCP tool auto-selects relevant files based on the task description and builds a focused codemap. Instead of dumping the entire repository, the agent gets exactly the files it needs.
The fork runs repoprompt_cli as a standalone MCP server alongside a Linear GraphQL bridge, both configured in .mcp.json:
{
"mcpServers": {
"linear_graphql": {
"command": "node",
"args": ["priv/mcp_bridge/linear_graphql_server.js"]
},
"RepoPrompt": {
"command": "repoprompt_cli",
"args": []
}
}
}There’s also a bootstrap hook: if CLAUDE.md doesn’t exist in the workspace, the after_create hook auto-generates one from the repo tree via rp-cli. Claude Code reads CLAUDE.md natively as its map of the codebase.
The Dispatch Router
The DispatchRouter is a clean piece — a pure-function module that maps issue states to actions:
DispatchRouter.route(%Issue{state: "Todo"})
# → {:plan, SymphonyElixir.AgentBackend.ClaudeCode, [max_turns: 5]}
DispatchRouter.route(%Issue{state: "In Progress"})
# → {:agent, SymphonyElixir.AgentBackend.ClaudeCode, [max_turns: 20]}Config-driven, no code changes needed. Supports five action types: agent, plan, review, gate (manual hold), and transition (auto-move). Adding a new Linear state is a YAML change.
Prompt Patterns Learned from OpenAI
OpenAI’s own Symphony WORKFLOW.md — roughly 330 lines of structured agent instructions — has some great patterns worth adopting.
The Workpad. Each agent maintains a single persistent Linear comment titled ”## Workpad” with a plan checklist, acceptance criteria, and validation results. Updated in-place throughout execution. This gives both the human and the agent a living document of progress.
Continuation context. When an agent gets a second turn, the prompt says: “This is retry attempt #N. Resume from current workspace state. Do not repeat already-completed investigation.” Simple, but it prevents agents from starting over after failures.
Plan handoff. The implementation prompt includes the full PLAN.md via a {{ implementation_plan }} template variable. The agent follows the plan instead of re-investigating from scratch.
Preventing Infinite Loops
A subtle but critical piece: smart dispatch guards.
Before dispatching a planning run, the orchestrator checks: Does PLAN.md already exist? Skip — planning is complete, waiting for human approval. Does QUESTIONS.md exist without a PLAN.md? Check for new human replies. No replies? Skip — still waiting for answers. New replies? Re-dispatch with the feedback.
When the implementation agent moves an issue to “In Review” via the Linear MCP tool, the multi-turn loop detects the state change and stops. Without this, you get agents burning tokens on issues that have already moved to a different phase.
Getting this wrong means infinite dispatch loops.
The Numbers
Here’s what the fork adds to the original Symphony codebase:
| What | Count |
|---|---|
| New Elixir modules | 7 |
| Lines added | ~4,000+ |
| Test coverage | 308 tests, 0 failures |
| Supported backends | 2 (Codex, Claude Code) |
| Pipeline phases | 3 |
| MCP integrations | 2 (Linear, RepoPrompt) |
The workflow goes from “pray the agent understands the ticket” to “review a structured plan, approve it, and watch the agent execute it.”
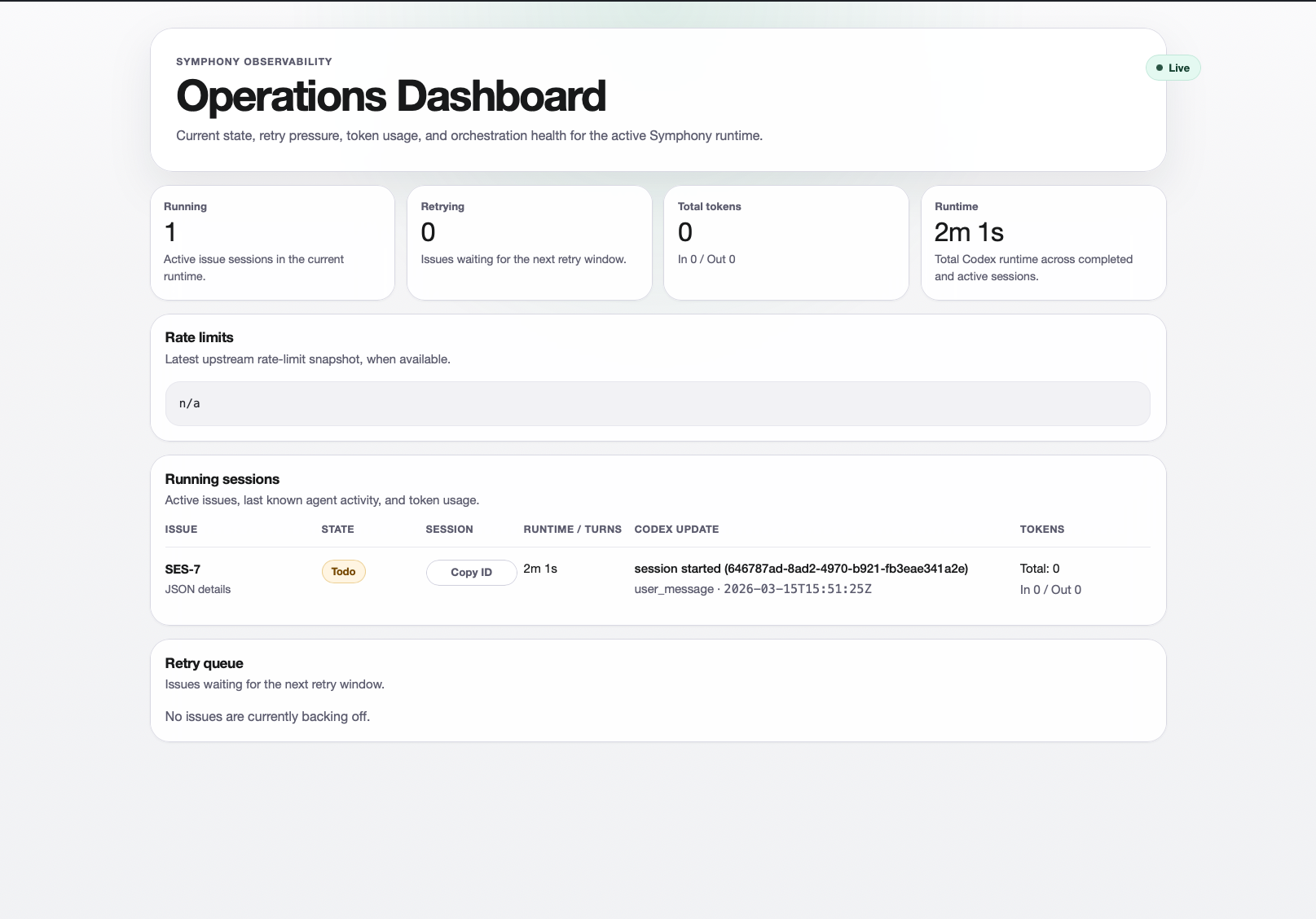
The Elephant in the Room: Tokens
Even with RepoPrompt, even with focused context building, even with session continuity — this thing eats tokens.
A medium-complexity issue easily burns $3–5 across the full Plan → Implement → Review cycle. A chunky one can hit $10+. And the worst part is where those tokens go: not on the actual coding, but on context. Every turn, the agent re-ingests the system prompt, the CLAUDE.md, the plan, the conversation history, the tool definitions. A 25,000-token project context re-sent across 5 agent turns is 125,000+ input tokens before the agent writes a single line of code.
Output tokens cost 3–10x more than input tokens across all providers. So when the implementation agent writes a verbose explanation before every code block, that’s the expensive side of the meter spinning.
There are a few directions worth exploring:
Prompt caching. Static content — system instructions, CLAUDE.md, tool definitions — placed at the beginning of the prompt can be cached by the provider. Cached tokens are ~75% cheaper. The catch: cache hits require exact prefix matches, so tools must be listed in consistent order every time. One reordering and the cache misses. Manus reportedly tracks cache hit rate as their single most important operational metric.
Context compression. LangChain’s Deep Agents SDK triggers summarization at 85% context utilization — distilling the conversation into a structured summary (intent, artifacts created, next steps) that replaces the full history. The goal is to build something similar into the orchestrator: when the agent’s context crosses a threshold, automatically compact before the next turn. Keep the plan and recent tool outputs, summarize everything else.
Model routing per phase. Not every phase needs the same model. Planning benefits from deep reasoning — that’s where Claude shines. But the review agent checking a diff against acceptance criteria? That could run on a cheaper, faster model. Even within a phase, simple classification tasks (is this file relevant?) don’t need the same compute as architectural decisions. A tiered approach where the orchestrator picks the model based on the action type could help a lot here.
Token budgets with hard stops. The Claude Code backend already tracks total_cost_usd per session. The orchestrator could inject a warning at 50% budget (“focus on completing the implementation”) and a hard stop at 100% (“wrap up and submit what you have”). Right now there’s no guardrail — an agent can spiral on a misunderstood test failure and burn $15 before anyone notices.
Harness Engineering: What’s Next
The agent model is a smaller part of the equation than you’d think. The harness — everything around the model — is where the real leverage is. OpenAI figured this out internally: they shipped a million lines of code using Codex by investing in harness engineering, not by waiting for a smarter model.
But the single most important next step isn’t about cost or plan quality. It’s about security.
Sandboxed execution per ticket. Right now, Symphony gives every agent full workspace access with bypassPermissions. That’s a real risk. An agent working on a CSS fix has the same filesystem access as one refactoring your auth module. A confused agent on ticket A can read, modify, or delete files that ticket B’s agent is actively working on. And if an agent gets tripped up by a weird repo pattern or a malicious dependency — it has the keys to the whole house.
Every ticket should run in its own isolated sandbox. No escalated permissions to the host system. Write access scoped to that ticket’s workspace and nothing else. Network access disabled by default (with explicit allowlists for package installation). Read-only access to shared project resources like the CLAUDE.md hierarchy and repo context. And critically — agent config files (.mcp.json, hooks, CLAUDE.md itself) should be read-only from inside the sandbox, because those are all attack surfaces for indirect prompt injection.
The tricky part is that tickets still need to share things. The review agent needs to see the implementation agent’s diff. The implementation agent needs to read the planning agent’s PLAN.md. Two agents working on related modules need access to the same source tree without stepping on each other. So the sandbox can’t be a total wall — it needs controlled, read-only sharing of specific artifacts between ticket workspaces.
The options include gVisor, Kata Containers, Firecracker, Docker’s new docker sandbox run, and even commercial sandboxes like E2B and Modal. Each has tradeoffs between isolation strength, startup latency, and compatibility with tools like git and mix. The goal is to make the default safe (locked down) and make opening things up an explicit, auditable decision per ticket. NVIDIA’s AI Red Team puts it well: “allow-once / run-many is not an adequate control.”
Beyond sandboxing, here are other concrete next steps:
Structured plans, not markdown. Right now PLAN.md is free-text markdown. The implementation agent infers structure from section headers like ”## Affected Files” and ”## Approach.” That’s fragile. Plans should be structured objects with explicit task statuses (pending, in_progress, completed, blocked), dependencies between tasks, and a hard enforcement gate that prevents the agent from calling “done” with incomplete items. Arize AI’s Alyx agent does exactly this with todo_write/todo_read tool calls instead of prompt instructions, and the results are significantly better.
Mechanical enforcement over prompt instructions. OpenAI’s sharpest insight from their harness engineering article: “If an architectural constraint matters enough to document, it matters enough to enforce with a linter.” This means pre-implementation hooks that validate the plan has test criteria, post-implementation hooks that run the test suite before creating a PR, and review hooks that check for common agent failure patterns. The linter error messages should contain remediation instructions — so when the agent hits a violation, the error itself teaches it how to fix the problem.
Multi-dimensional review. The current binary APPROVED/CHANGES_REQUESTED leaves value on the table. The review agent should score across multiple dimensions independently: correctness (does it match the plan?), test coverage, lint compliance, architectural boundaries. Each dimension gets targeted feedback. Only when all pass does the review approve. Failed dimensions return specific, actionable feedback — not “please fix” but “function X on line Y doesn’t handle the nil case specified in plan task #3.”
Progressive CLAUDE.md. Right now the auto-generated CLAUDE.md is a flat repo tree dump. OpenAI’s production repo uses 88 separate AGENTS.md files — one per subsystem — with the root file as a ~100-line map pointing to deeper docs. The better model is a lean root CLAUDE.md with pointers, and per-module files that load on-demand so the agent only ingests context relevant to the current task. Every token in that auto-injected file competes directly with the task context.
Cross-session knowledge. Right now, every agent starts fresh. If the planning agent discovers that “the auth module has a non-obvious dependency on the config loader,” that insight dies with the session. Completed plans should be committed to a docs/exec-plans/completed/ directory so future planning agents can reference patterns that worked. And a “lessons learned” file that the review agent updates when it spots recurring issues — evolving project-specific guidance that gets better with every issue.
Try It Yourself
If you want to try this workflow:
- Set up a Linear project with Todo, In Progress, and In Review states.
- Configure
WORKFLOW.mdwith the three-phase pipeline pointing to Claude Code. - Install cmux for agent visibility (optional — falls back to headless).
- Run
./bin/symphony ./WORKFLOW.mdand watch your board come alive.
The most surprising thing about this project isn’t the technology. It’s how natural it feels to manage AI agents through the same Kanban board you already use. The board becomes the interface. Linear comments become the communication channel. Plans become the contract between my intent and the agent’s execution.
What I’ve found is that the best AI developer tools don’t invent new workflows. They fit into the ones you already have.